Examining crime trends in your local area can be a daunting task, especially when the data is constantly evolving. Fortunately, with the right tools and techniques, you can automate the process of analyzing this data, ensuring that your insights remain current without the need for repetitive manual work. This article outlines how to create a data pipeline to extract local police log data and visualize it effectively, using the Cambridge Police Department (CPD) as a case study.
Background Knowledge
Before embarking on this journey, it’s beneficial to familiarize yourself with some key concepts related to data extraction, transformation, and loading (ETL). Keeping these references handy will aid your understanding as we progress through the pipeline implementation.
Data of Interest
The dataset we will utilize consists of police log entries from the CPD, where each entry represents a reported incident. Each log entry includes:
- Date & time of the incident
- Type of incident
- Location of the incident
- A detailed description of the incident
For more information about the dataset, you can visit the data portal.
Since the data is updated daily, establishing an automated pipeline is advantageous. If the updates were less frequent, manual downloads would suffice.
ETL Pipeline
Our project will follow a structured ETL process, which includes the following steps:
- Extracting data via the Socrata Open Data API
- Transforming the data for optimal storage
- Loading the data into a PostgreSQL database
- Visualizing the data using Metabase
The data flow will illustrate how we transition from raw data to a visual dashboard.
To extract the CPD log data, we will utilize the Socrata Open Data API and employ sodapy, a Python client for the API. The extraction code will be encapsulated in a file named extract.py.
import pandas as pd
from sodapy import Socrata
from dotenv import load_dotenv
import os
from prefect import task
@task(retries=3, retry_delay_seconds=[10, 10, 10])
def extract_data():
load_dotenv()
APP_TOKEN = os.getenv("SOCRATA_APP_TOKEN")
client = Socrata("data.cambridgema.gov", APP_TOKEN, timeout=30)
DATASET_ID = "3gki-wyrb"
results = client.get_all(DATASET_ID)
results_df = pd.DataFrame.from_records(results)
return results_df
Next, we will perform basic data validation checks to ensure the integrity of the data. This involves confirming the presence of expected columns, verifying that IDs are numeric, ensuring datetimes conform to ISO 8601 format, and checking for missing values. The validation code will reside in a file named validate.py.
from datetime import datetime
from collections import Counter
import pandas as pd
from prefect import task
@task
def validate_data(df):
SCHEMA_COLS = ['date_time', 'id', 'type', 'subtype', 'location', 'last_updated', 'description']
if Counter(df.columns) != Counter(SCHEMA_COLS):
raise ValueError("Schema does not match with the expected schema.")
df['id'] = pd.to_numeric(df['id'], errors='coerce')
df.apply(lambda row: datetime.fromisoformat(row['date_time']), axis=1)
REQUIRED_COLS = ['date_time', 'id', 'type', 'location']
for col in REQUIRED_COLS:
if df[col].isnull().sum() > 0:
raise ValueError(f"Missing values are present in the '{col}' attribute.")
return df
Following validation, we will transform the data to prepare it for storage in PostgreSQL. This includes removing duplicates, invalid rows, and splitting the datetime column into separate components. The transformation logic will be housed in transform.py.
import pandas as pd
from prefect import task
@task
def transform_data(df):
df = df.drop_duplicates(subset=["id"], keep='first')
df = df.dropna(subset='id')
df['date_time'] = pd.to_datetime(df['date_time'])
df['year'] = df['date_time'].dt.year
df['month'] = df['date_time'].dt.month
df['day'] = df['date_time'].dt.day
df['hour'] = df['date_time'].dt.hour
df['minute'] = df['date_time'].dt.minute
df['second'] = df['date_time'].dt.second
return df
Once the data is transformed, we will load it into our PostgreSQL database. This requires creating a PostgreSQL instance using Docker and executing SQL queries to create the necessary table and insert the data. The loading logic will be implemented in load.py.
from prefect import task
from sqlalchemy import create_engine
import psycopg2
from dotenv import load_dotenv
import os
@task
def load_into_postgres(df):
load_dotenv()
conn = psycopg2.connect(
host="localhost",
port="5433",
database="cpd_db",
user=os.getenv("POSTGRES_USER"),
password=os.getenv("POSTGRES_PASSWORD")
)
cur = conn.cursor()
create_table_query = '''
CREATE TABLE IF NOT EXISTS cpd_incidents (
date_time TIMESTAMP,
id INTEGER PRIMARY KEY,
type TEXT,
subtype TEXT,
location TEXT,
description TEXT,
last_updated TIMESTAMP,
year INTEGER,
month INTEGER,
day INTEGER,
hour INTEGER,
minute INTEGER,
second INTEGER
)
'''
cur.execute(create_table_query)
conn.commit()
cur.close()
conn.close()
engine = create_engine(f"postgresql://{os.getenv('POSTGRES_USER')}:{os.getenv('POSTGRES_PASSWORD')}@localhost:5433/cpd_db")
df.to_sql('cpd_incidents', engine, if_exists='replace')
With the individual components of the ETL process implemented, we can now encapsulate them into a cohesive pipeline using Prefect. This orchestration will allow us to automate the execution of our data pipeline on a daily basis.
from extract import extract_data
from validate import validate_data
from transform import transform_data
from load import load_into_postgres
from prefect import flow
@flow(name="cpd_incident_etl", log_prints=True)
def etl():
extracted_df = extract_data()
validated_df = validate_data(extracted_df)
transformed_df = transform_data(validated_df)
load_into_postgres(transformed_df)
if __name__ == "__main__":
etl.serve(name="cpd-pipeline-deployment", cron="0 0 * * *")
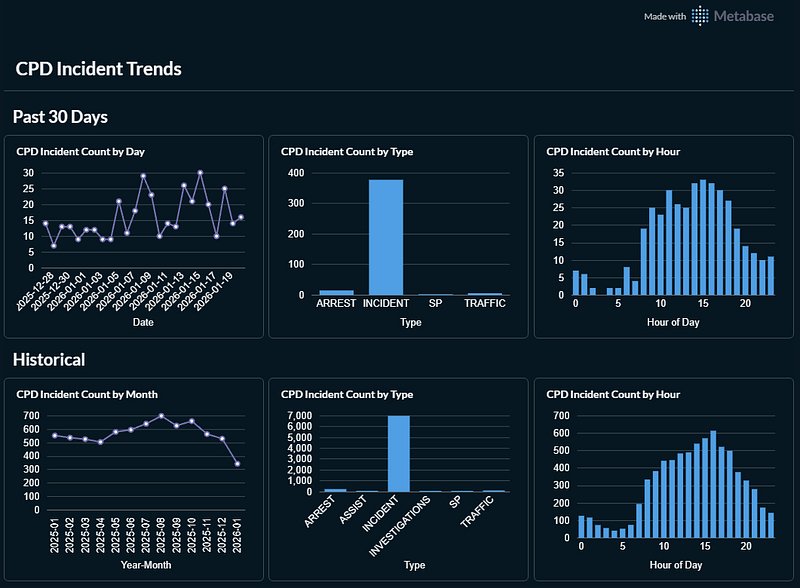
Finally, we will visualize the data using Metabase, an open-source business intelligence tool that simplifies data visualization. We will set up a self-hosted instance of Metabase using Docker, connect it to our PostgreSQL database, and create a dashboard to display crime trends over time.
services:
metabase:
image: metabase/metabase:latest
container_name: metabase
ports:
- "3000:3000"
environment:
MB_DB_TYPE: postgres
MB_DB_DBNAME: metabaseappdb
MB_DB_PORT: 5432
MB_DB_USER: ${METABASE_DB_USER}
MB_DB_PASS: ${METABASE_DB_PASSWORD}
MB_DB_HOST: postgres_metabase
After setting up Metabase, you can connect it to your PostgreSQL instance using the connection string provided. This will allow you to create various visualizations, including a dashboard that summarizes recent and historical trends in CPD incidents.
With this automated pipeline in place, you can continuously monitor crime trends in your area, gaining valuable insights without the burden of manual data analysis. For those interested in further exploration, consider extending the project with additional visualizations or integrating other datasets for a more comprehensive analysis.
For a deeper dive into the implementation, you can access the GitHub repository here.