Tech Optimizer
April 11, 2026
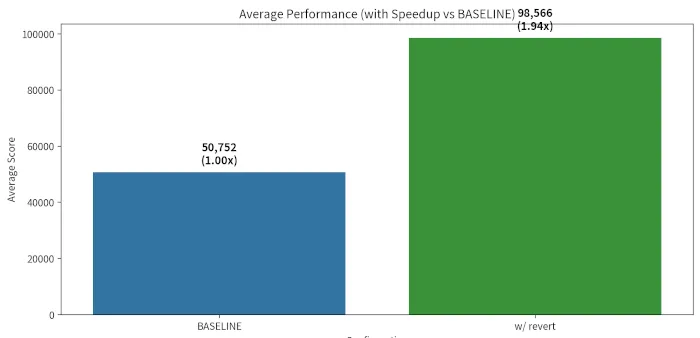
Enterprises in Malaysia are transitioning from legacy systems to modern infrastructure to facilitate AI deployment. A roundtable discussion highlighted the challenges of AI integration, emphasizing the need to reduce costs associated with outdated systems. Organizations are adopting hybrid cloud approaches and utilizing various databases to manage extensive data across multiple applications. The push for AI is driven by management and customer expectations, but employee willingness to upskill remains a challenge. Not all challenges require AI solutions, and starting with smaller use cases can lead to successful scaling. The adoption of open-source database systems like Postgres is increasing, necessitating reliable support to address issues and ensure application availability. Data sovereignty is a concern for enterprises operating in mixed environments, and EDB Postgres AI offers a platform that combines security with cloud agility. Reducing infrastructure costs is essential for freeing up resources for new initiatives.