Tech Optimizer
July 29, 2026
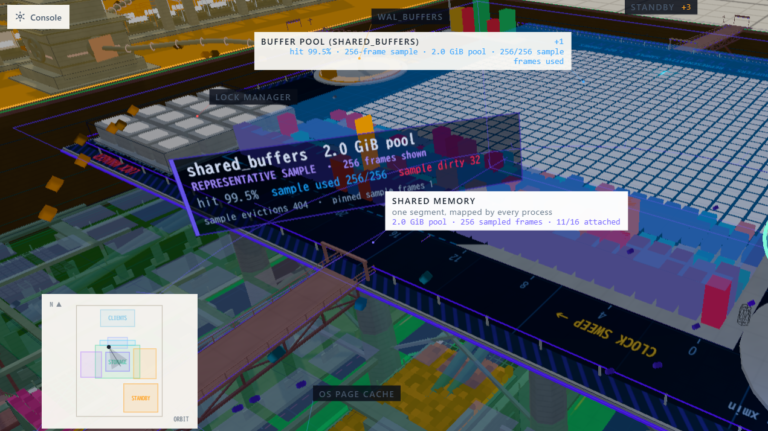
Cloud database provider Turso is developing a Postgres-compatible implementation based on its SQLite-compatible database, which was created from scratch in Rust. CEO Glauber Costa believes Postgres can benefit from modernization for cloud-native applications. Turso's SQLite reimplementation, now called Turso, uses a virtual machine architecture that may eventually support other database frontends, including MySQL and Redis. The company initially forked SQLite into libSQL but later pivoted to a cloud service named Turso. They focused on a virtual machine architecture for their rewrite, which translates SQL queries into a custom bytecode language. Turso has developed a Postgres-compatible prototype named pgmicro, which aims to run existing applications with minimal modifications. The company is also working on a database-as-a-cloud service that will allow customers to use various database types on the Turso platform.