Tech Optimizer
April 11, 2026
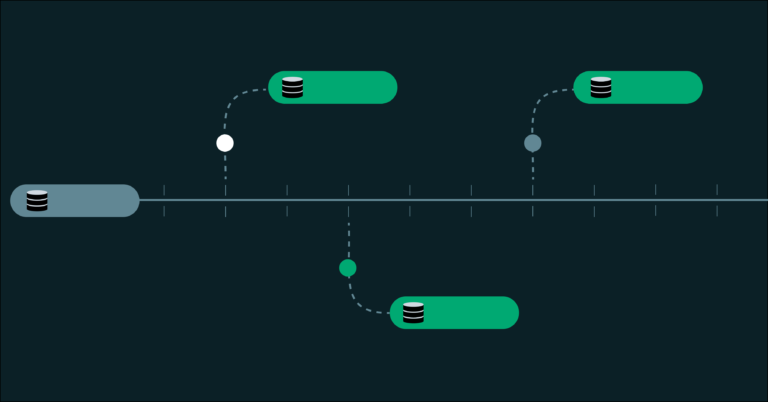
Database branching is a modern approach that addresses the limitations of traditional database management in development workflows. Unlike conventional database copies, which require significant time and resources to duplicate data and schema, database branching allows for the creation of isolated environments that share the same underlying storage. This method utilizes a copy-on-write mechanism, enabling branches to be created in seconds regardless of database size, with storage costs tied only to the changes made.
Key features of database branching include:
- Branch creation time: Seconds, constant regardless of database size.
- Storage cost: Proportional to changes only, not the total data size.
- Isolation: Each branch has its own Postgres connection string and compute endpoint.
- Automatic scaling: Idle branches can scale compute to zero, incurring costs only when active.
The architecture supporting this approach separates compute from storage, allowing multiple branches to reference the same data without conflict. This design facilitates time travel capabilities, enabling branches to be created from any point in the past for instant recovery and inspection.
Database branching unlocks new workflows, such as:
- One branch per developer, providing isolated environments for each engineer.
- One branch per pull request, automating branch creation and deletion tied to PRs.
- One branch per test run, provisioning fresh databases for each CI pipeline execution.
- Instant recovery from any point in time within a designated restore window.
- Ephemeral environments for AI agents, allowing programmatic database provisioning.
Databricks Lakebase offers this database branching capability, transforming the database from a bottleneck into a streamlined component of the development process.