Winsage
July 15, 2026
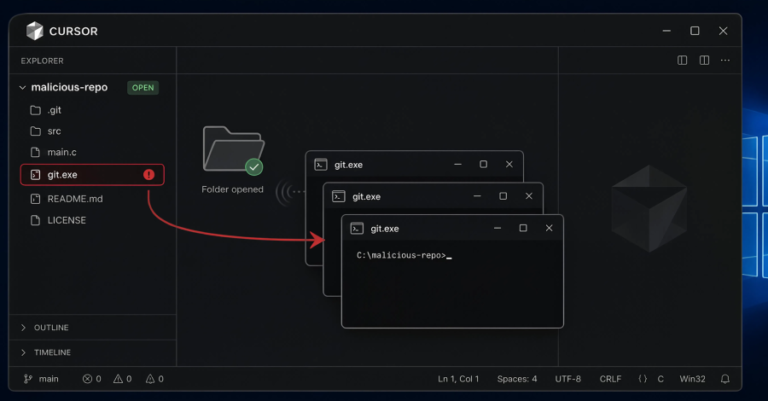
Cursor, a development tool, has a security vulnerability that allows arbitrary code execution by simply opening a project repository on Windows. This flaw, reported by AI security firm Mindgard, is due to the presence of a file named git.exe in the project root, which Cursor executes automatically without user prompts. Mindgard demonstrated this vulnerability by renaming Windows Calculator to git.exe and placing it in the project root, leading to multiple instances of Calculator launching upon opening the repository. Cursor has not yet released a patch or advisory for this issue, which was first reported on December 15, 2025, and remains in the latest version, 3.11, released on July 10, 2026. Users are advised to implement workarounds, such as using AppLocker or Windows App Control to block executables by name and path. Other vendors, including GitHub and Google, have encountered similar vulnerabilities, but none have released fixes. The issue highlights the risks associated with untrusted search paths in software development.