The current landscape of artificial intelligence interactions for many users revolves around cloud-based tools like ChatGPT and Copilot. These platforms, while accessible from virtually any device, necessitate a reliable internet connection. However, a segment of users, particularly developers, seeks a more autonomous experience by running large language models (LLMs) locally on their machines. This is where Ollama steps in, providing an efficient solution for those who prefer to keep their AI capabilities close to home.
To effectively run LLMs, one must consider hardware requirements. The larger the model, the more computational power is essential. Currently, these models require a GPU for optimal performance, as they have not yet been fine-tuned for use on NPUs found in newer Copilot+ PCs. Nevertheless, for those with modest setups, smaller models are available. For instance, Google’s Gemma 3 offers a 1 billion parameter model that requires only 2.3GB of VRAM, while the 4 billion parameter version demands over 9GB. Similarly, Meta’s Llama 3.2 provides a 1 billion parameter model that runs on a 4GB VRAM GPU, increasing to 8GB for the 3 billion parameter model. Essentially, a modern PC equipped with at least 8GB of RAM and a dedicated GPU can leverage Ollama’s capabilities effectively.
How to install Ollama on Windows 11
Installing Ollama on Windows 11 is a straightforward process. Users simply need to download the installer from the official website or GitHub repository and proceed with the installation. Once installed, Ollama operates seamlessly in the background, and users might not notice any immediate changes on their desktop. However, its presence is indicated by an icon in the taskbar, and its functionality can be verified by navigating to localhost:11434 in a web browser.
Installing and running your first LLM on Ollama
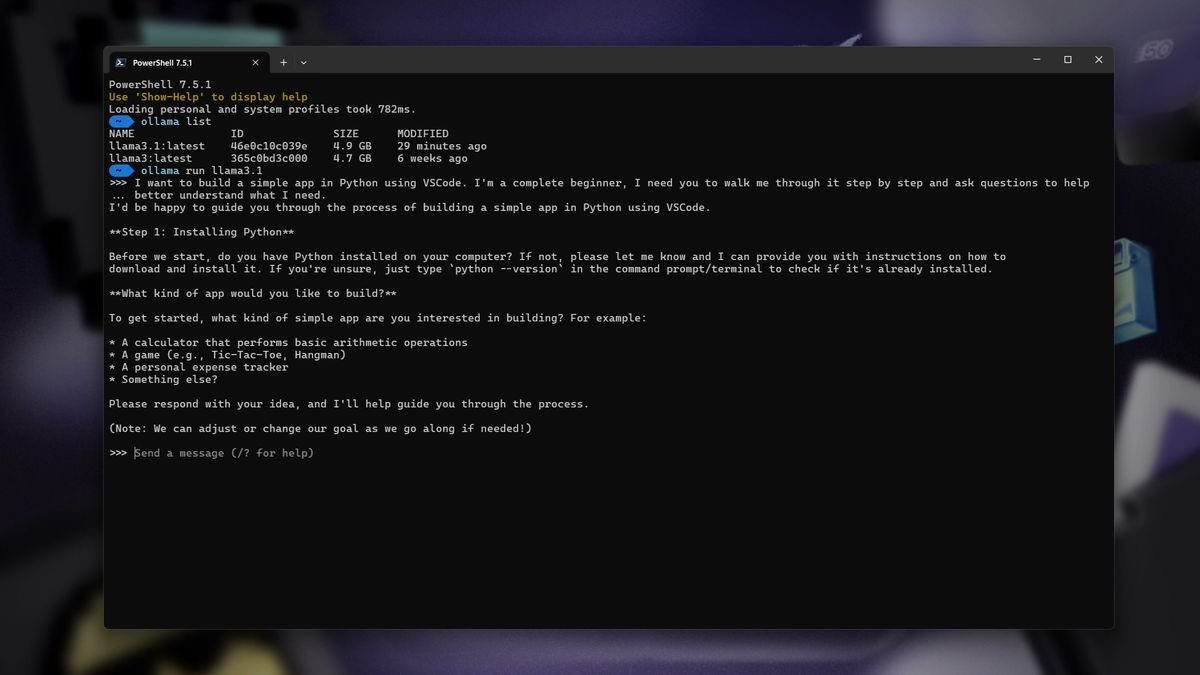
Ollama primarily features a command-line interface (CLI), which requires users to access PowerShell or WSL if that’s where the installation occurred. While a graphical user interface (GUI) is available, familiarity with the CLI can be beneficial. The two essential commands to master are:
ollama pull
ollama run When requesting to run an LLM that isn’t currently installed, Ollama intelligently fetches it before execution. Users need only to know the correct name of the desired LLM, which can be found on the Ollama website. For example, to install the 1 billion parameter Google Gemma 3 LLM, one would enter:
ollama pull gemma3:1b By appending :1b to the name, users specify their preference for the 1 billion parameter model. To opt for the 4 billion parameter model, simply change it to :4b. Running the models through the terminal opens a familiar chatbot interface, allowing users to input prompts and receive responses—all executed locally on their machines. To exit the model and return to PowerShell, users can simply type /bye.
Overall, setting up Ollama on a PC to access a variety of LLMs is a straightforward and user-friendly experience, requiring minimal technical expertise. If navigating this process seems daunting, rest assured that with a little guidance, anyone can successfully harness the power of local AI.