Sixteen years ago, as I embarked on my PhD journey at UC Berkeley, my advisor offered a piece of advice that would shape my path: “OLTP databases are a solved problem. They work. Focus on analytics.” At that time, we were just beginning to harness the potential of vast amounts of structured and unstructured data, alongside the burgeoning field of machine learning, now widely referred to as AI. Heeding this guidance, I joined my cofounders in a research project that ultimately led to the creation of Apache Spark and the establishment of Databricks.
Throughout the development of Databricks, we engaged with various databases and soon discovered that OLTP databases were far from being a solved issue. They proved to be cumbersome, challenging to scale, and remarkably fragile. This realization sparked a pivotal question: what would an OLTP database look like if we were to design it with today’s technology? This inquiry culminated in the creation of Lakebase, our innovative serverless Postgres database.
This article delves into the architecture of Lakebase OLTP. We begin by examining the storage layer of traditional monolithic databases to identify existing pain points, then explore how Lakebase reconfigures these components into independent, externalized services. Finally, we discuss LTAP, which leverages this architecture to enable transactions and analytics to operate on a single data copy in real time, eliminating the delays and costs associated with change data capture (CDC) or data mirroring.
The database as a monolith
The majority of databases in use today, including MySQL, Postgres, and classic Oracle, are monolithic in nature. Lakebase is built on Postgres, which, interestingly enough, also originated at Berkeley. In these systems, a single machine is provisioned to run both the database engine and the storage. Two critical components reside on disk: the write-ahead log (WAL) and the data files.
When a transaction is committed, the database does not immediately rewrite the data files. This would be inefficient, as the affected rows are often scattered across the file, necessitating random I/O. Instead, the database appends a description of the change to the WAL, a sequential log on disk. A transaction is deemed committed once this log entry is durably written. Only later, asynchronously, does the database update the actual data files to reflect the change.
To simplify: the WAL is designed to make writes fast and safe, while the data files are optimized for fast reads. The log allows for a single sequential append to commit a transaction, avoiding the inefficiencies of random I/O. Conversely, the data files enable quick query responses by reading the current state directly, rather than replaying the entire history of the database. For those interested in the intricate details of this design, I recommend the 69-page ARIES paper, albeit with a warning that it is one of the more complex reads in computer science.
While this design has become foundational for nearly all databases, the monolithic architecture presents several challenges:
- Data loss from misconfiguration: A commit’s durability is only as reliable as the disk flush behind it. If the database, operating system, or storage layer is misconfigured, a write to the WAL may be acknowledged before it is flushed to durable media, risking data loss during power failures or kernel panics.
- Data loss from node failure: Even with proper flush configurations, both the WAL and data files reside on a single machine. If that machine’s disk fails, the data is lost. While techniques like RAID can enhance durability, they do not fundamentally resolve this issue.
- Scaling reads necessitates physical cloning: When a single machine can no longer handle traffic, the typical solution is to add a read replica. However, this requires creating a full physical copy of the database, which can be time-consuming and disruptive.
- High availability requires physical duplication: To survive the loss of the primary node, at least one additional standby node must be maintained, incurring additional costs and complexity.
- Analytics compete with transactional traffic: Heavy analytical queries can degrade the performance of latency-sensitive transactional workloads, necessitating separate replicas that still do not optimize performance.
These challenges stem from the same root cause: the WAL and data files are confined to a single machine. Durability relies on that machine’s disk, scaling and availability require physical duplication, and workloads interfere due to shared resources.
Lakebase architecture
If we were to redesign an OLTP database today, we would leverage the components of modern cloud infrastructure: affordable and highly durable cloud object storage combined with elastic compute resources. This was the approach taken by the Neon team, forming the foundation of Lakebase.
The core innovation involves making Postgres compute instances stateless. This is achieved by externalizing the WAL and data files from local disks into dedicated, independently scalable services. Consequently, the compute layer transforms into a stateless Postgres engine, capable of being started, stopped, and replicated freely, as it no longer retains ownership of the data.
Let us explore how these two storage services collaborate to address the aforementioned challenges without compromising performance.
Scaling writes: WAL becomes SafeKeeper
In a monolithic setup, durability is achieved by flushing writes to local disk. In Lakebase, the WAL is externalized to a distributed storage service known as SafeKeeper. Instead of relying on disk flushes for durability, a commit is made durable by replicating the log record across a quorum of SafeKeeper nodes using Paxos-based network replication. This eliminates the risk of data loss due to disk failure or misconfiguration.
One might wonder if moving commits from a local disk WAL to SafeKeeper increases write latency due to the additional network hop. The answer is no. For any serious Postgres deployment prioritizing durability and availability, synchronous replication is necessary, which inherently involves a network hop. Thus, externalizing the WAL into SafeKeeper does not introduce additional latency. In fact, the combination of SafeKeeper and PageServer can yield 5X higher write throughput and 2X lower read latency.
Scaling reads: data files become PageServer
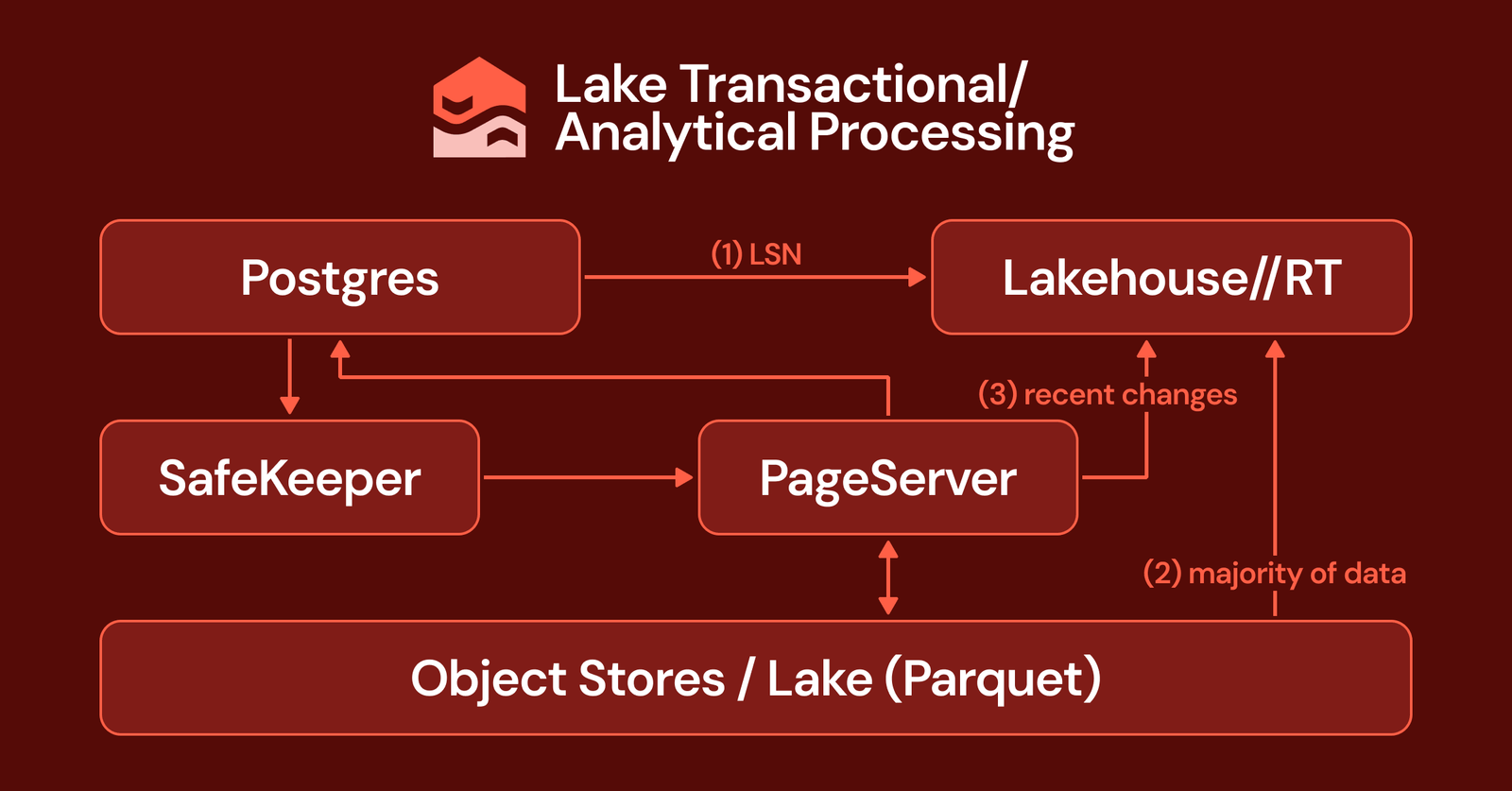
The data files are transitioned to another distributed storage service called PageServer. The WAL is streamed from SafeKeeper into PageServer, which asynchronously applies changes to its version of the data, materializing pages into low-cost cloud object storage (the lake). You can envision the PageServer as a write-through cache for the underlying object storage.
This setup mirrors the WAL-data files relationship of the monolith, but now the two components reside in separate, independently scalable services connected via the network. When a page is requested from PageServer, if the latest version is not available, the PageServer retrieves the logs from SafeKeeper to reconstruct the current state.
Again, one might question whether moving data files from local disks to PageServer increases read latency due to the network hop. The answer remains no for practical purposes. The system is designed to minimize latency through aggressive, multi-layered caching. When fetching a page, Postgres first checks its buffer pool in local memory. If the page is not present, it checks a local disk cache, resorting to PageServer only in the event of a cache miss. Since a compute node can be configured with local memory and disk capacities comparable to a monolithic setup, the local cache hit rate remains unchanged. For the majority of operations, read latency is indistinguishable from that of a monolith, while benefiting from virtually limitless storage.
What this unlocks
With the WAL residing in SafeKeeper and data files in PageServer, a plethora of capabilities that were previously challenging or impossible in the monolith become inherent to the architecture. The following features are already available as part of the Lakebase product on both Databricks and Neon:
- Still Postgres: This is authentic Postgres, ensuring that the wire protocol, SQL, drivers, and extensions function seamlessly.
- Unlimited storage: Data is stored in cloud object storage rather than on a fixed local disk, eliminating capacity constraints.
- Serverless, elastic compute: As compute is stateless, it can scale up instantly under load and scale down to zero when idle, reducing costs.
- Durable writes and zero data loss: A commit is durable once replicated across SafeKeeper nodes, independent of any single local disk.
- Simpler high availability: High availability no longer necessitates maintaining a second full physical clone, as the durable state resides in a replicated storage layer.
- Instant branching, cloning, and recovery: Cloning a large production database becomes a metadata operation rather than a physical copy, allowing for rapid experimentation and recovery.
While separating compute from storage is not a novel concept, previous discussions have highlighted generation 2 cloud databases that have adopted this approach. However, Lakebase distinguishes itself by storing operational data in commodity object storage using an open format, paving the way for other engines to access it directly, which leads us to LTAP.
LTAP: one copy for transactions and analytics
Thus far, we have focused on enhancing a single operational database—making it more durable, elastic, cost-effective, and faster to branch. However, once data resides in an externalized storage layer, we can transcend the traditional separation between transactional databases and analytical systems.
Returning to the PageServer, it already streams changes from the WAL and asynchronously materializes pages into object storage. This materialization step, where data lands in the lake, presents an opportunity to address an age-old challenge.
Even with Lakebase, the data in object storage was initially written in Postgres’s native page format, organized row by row. While this format is optimal for transactions, it is less suitable for analytics, necessitating either a conversion cost on each read or reliance on a separate data copy maintained by a pipeline. Such pipelines can be fragile, leading to governance issues with diverged permissions.
We recently introduced LTAP (Lake Transactional/Analytical Processing), which resolves the dual-copy data issue. The key innovation is to unify the transactional and analytical worlds at the storage layer instead of at the engine layer. We do not attempt to create a single engine that excels at both transactions and analytics; instead, we utilize the best tools for each task: Postgres for transactions, with full ACID semantics, and Lakehouse engines for analytics. The data beneath them is unified, comprising one durable copy in open columnar formats like Delta and Iceberg, stored as Parquet, accessible to both sides with various caching levels for enhanced performance.
Materializing in columnar form
Note: This section requires a deeper understanding of Postgres internals than previous sections.
As the PageServer materializes pages into object storage, it transcodes Postgres data from a row format into Parquet’s columnar layout. We preserve the exact Postgres representation of every value, down to the bits, allowing any Postgres-compatible engine to reinterpret it without losing information. This approach differs from CDC, which sends a stream of logical change events into a foreign schema, abandoning Postgres’s physical and transactional semantics. Here, we maintain those semantics. The PageServer, equipped with a hyperoptimized engine, performs the row-to-columnar transcoding during the materialization process, imposing no burden on the Postgres compute handling transactions. To efficiently serve transactional reads, the PageServer still materializes traditional row-based pages in a local cache, but this serves purely as a performance enhancement. The underlying durable store remains unified in the lake, accessible by both transactional and analytical engines.
Preserving Postgres semantics in columnar form hinges on two aspects: the type system and multi-versioning.
- Type system: Most Postgres types map directly to native Parquet types. For types without lossless columnar counterparts, such as NaN and ±Infinity, we retain them alongside the original columns in a structured overflow field within the same table, maintaining the canonical Postgres text for those values. This field is directly queryable by any engine and can reconstruct the original Postgres bytes when needed.
- Multi-versioning: Postgres retains every row version observable by transactions, enabling snapshot isolation and point-in-time recovery. In contrast, open table formats provide consistent snapshots without intermediate row versions. We achieve the benefits of both approaches by separating durability from visibility. Each row materialized to columnar form carries its physical heap address, ensuring that heap pages remain fully reconstructable. The classic Postgres heap page serves as a cache to accelerate point reads, while the durable source of truth resides in the columnar files in object storage. Postgres indexes are not transcoded into columns; they are served and rebuilt from the hot cache tier. Intermediate row versions are preserved to maintain Postgres’s MVCC semantics and point-in-time recovery, but they remain hidden from Iceberg/Delta readers and are eventually garbage-collected. The outcome is that analytical engines access clean, snapshot-consistent tables, while the underlying Postgres system retains a complete, time-travelable version history.
Additionally, a beneficial side effect arises: columnar data compresses significantly better than row data, often by a factor of more than ten. This conversion to columnar storage substantially reduces the volume of data traversing the network between the caching layer and the object store, rendering it negligible. The format that enhances analytics also optimizes the storage path.
Reading the latest data without affecting Postgres
A significant challenge lies in ensuring freshness. If analytics read from a copy in the lake, how can it access data committed moments ago that has not yet been materialized in the object store? This dilemma often undermines “just point analytics at the lake” designs, making it essential to understand how LTAP addresses this issue.
When an analytical query initiates, such as from the Lakehouse//RT product recently announced, it first queries Postgres for the current log sequence number (LSN), marking the precise position in the WAL to read from. This is a straightforward metadata lookup. With the LSN, the analytical engine retrieves the majority of the data, including everything materialized up to that point, directly from object storage. The only remaining task is to fetch a small set of very recent changes that have not yet been materialized in the lake, which it retrieves from the PageServer and merges on top.
The result is a consistent, fully up-to-date read of your data as of that LSN, with the bulk of the processing occurring on cost-effective, scalable object storage. Crucially, Postgres itself handles none of the analytical read traffic beyond returning the single LSN value. Consequently, your transactional workload remains unaffected by large analytical queries.
One practical optimization worth noting: for very small tables containing only a handful of rows, we do not convert them to columnar form or create associated Iceberg metadata. The overhead would outweigh the benefits, and such small tables have negligible impact on analytical performance regardless of their layout.
Every table, automatically
Given the significance of this issue, there has been considerable discussion in the market regarding the integration of OLTP and analytics. A traditional approach involves CDC, which effectively replicates data from OLTP storage into a separate analytics storage tier, often referred to as “mirroring,” “zero CDC,” or “zero ETL.”
In CDC or mirroring, the data replication pipeline incurs costs, making it impractical to apply to all tables. Users must explicitly select which tables to replicate, and this process typically introduces delays.
LTAP, however, requires no opt-in. Any existing table is, by design, already in the lake and readily queryable. There is no need for a list of replicated or mirrored tables, as replication is nonexistent. A single governed copy of the data exists in open formats, with no ETL pipeline to construct, monitor, or maintain. The transactional and analytical engines can scale independently, each tailored to its specific workload. Moreover, since there is no data movement and no second copy, the two views can never diverge: analytics consistently reads the same data that the application just wrote.
For further insights into how LTAP functions, consider watching this demo from the Data and AI Summit.
What about HTAP?
For those familiar with the field, it is evident that LTAP is a deliberate play on HTAP: hybrid transactional/analytical processing. HTAP has long been considered the holy grail of database engineering, aiming to create a single engine capable of handling both transactional and analytical workloads.
In practice, however, no widely adopted HTAP database system has emerged. This can be attributed to several factors:
- Incomplete feature set: Designing a new proprietary engine from scratch for a single task requires a multi-year investment. Attempting to create a single engine that performs multiple functions compounds the investment needed to achieve the feature set that engineers expect from a mature database. Consequently, these systems often lag in essential capabilities, from SQL support to query optimization maturity.
- No ecosystem: Postgres and Spark are at the center of vast ecosystems comprising drivers, extensions, tools, and decades of accumulated operational knowledge. A brand-new engine starts from scratch, and its utility is contingent on the ecosystem it can cultivate.
- No performance isolation: Many HTAP systems execute transactions and analytics on the same hardware, leading to contention for CPU and memory resources. This mirrors the issues we encountered in the monolith, where analytical queries could starve transactional workloads.
All three challenges stem from the decision to unify both workloads into a single engine. Lakebase and LTAP circumvent these issues by integrating at the storage layer while employing distinct compute engines for different workloads, leveraging their full feature sets and ecosystem support, all while ensuring performance isolation.
Reflecting on the introduction of the Lakebase architecture last year, we recognized that it would unlock unlimited storage, elastic compute, durable writes, simpler high availability, and instant branching, based on our experiences with the Neon platform. These capabilities emerged almost naturally once the WAL was housed in SafeKeeper and data files in PageServer.
The concept of LTAP developed later, as the Neon and Databricks teams collaborated to tackle the long-standing challenge of executing analytics against the most current transactional data. As we refine LTAP and roll it out in the coming months, all Lakebase tables will be readily available for analytics, performing at a level comparable to Lakehouse data.
What excites me most is the potential that lies ahead. While LTAP represents a natural progression, the same architecture also opens avenues for optimizing other resource-intensive maintenance operations separate from core transactional workloads. We are just beginning to explore the possibilities this architecture presents and eagerly anticipate sharing our future developments.
Special thanks to the Lakebase team for bringing these concepts to life, reviewing this article, and ensuring the technical details are accurate.