The database is the last bottleneck in your dev workflow
In the landscape of modern development workflows, database branching emerges as a pivotal yet often overlooked component. While various elements of the tech stack have adapted to facilitate rapid iteration—code management through Git, infrastructure as code with Terraform, and swift CI/CD pipelines—relational databases remain entrenched in outdated practices reminiscent of a decade ago.
Typically, development teams rely on a singular staging database, which, shortly after its creation, begins to drift from the production environment. This divergence manifests as discrepancies in schemas due to migrations being applied in inconsistent sequences, leading to mismatched sequence values and the accumulation of test data that taints results. Eventually, a team member must reseed the database, only to find themselves caught in a repetitive cycle.
The process of establishing a new environment is equally cumbersome. The conventional method involves executing a pg_dump against the production database, a task that can take anywhere from minutes to hours depending on the database’s size. Following this, the data must be loaded into a new instance, access configurations set up, and one can only hope that the outcome accurately reflects the production state. For a 500GB database, this translates to a time-consuming 500GB copy operation, alongside the requisite compute and storage resources to maintain it.
This predictable scenario leads teams to shy away from creating new environments due to the associated costs and delays. Developers often find themselves sharing a single mutable staging database, where migrations are either tested against outdated data or not tested at all. Preview deployments frequently rely on empty fixtures rather than realistic schemas, resulting in CI tests that share state and yield unreliable outcomes.
Consequently, the database becomes a source of trepidation for developers.
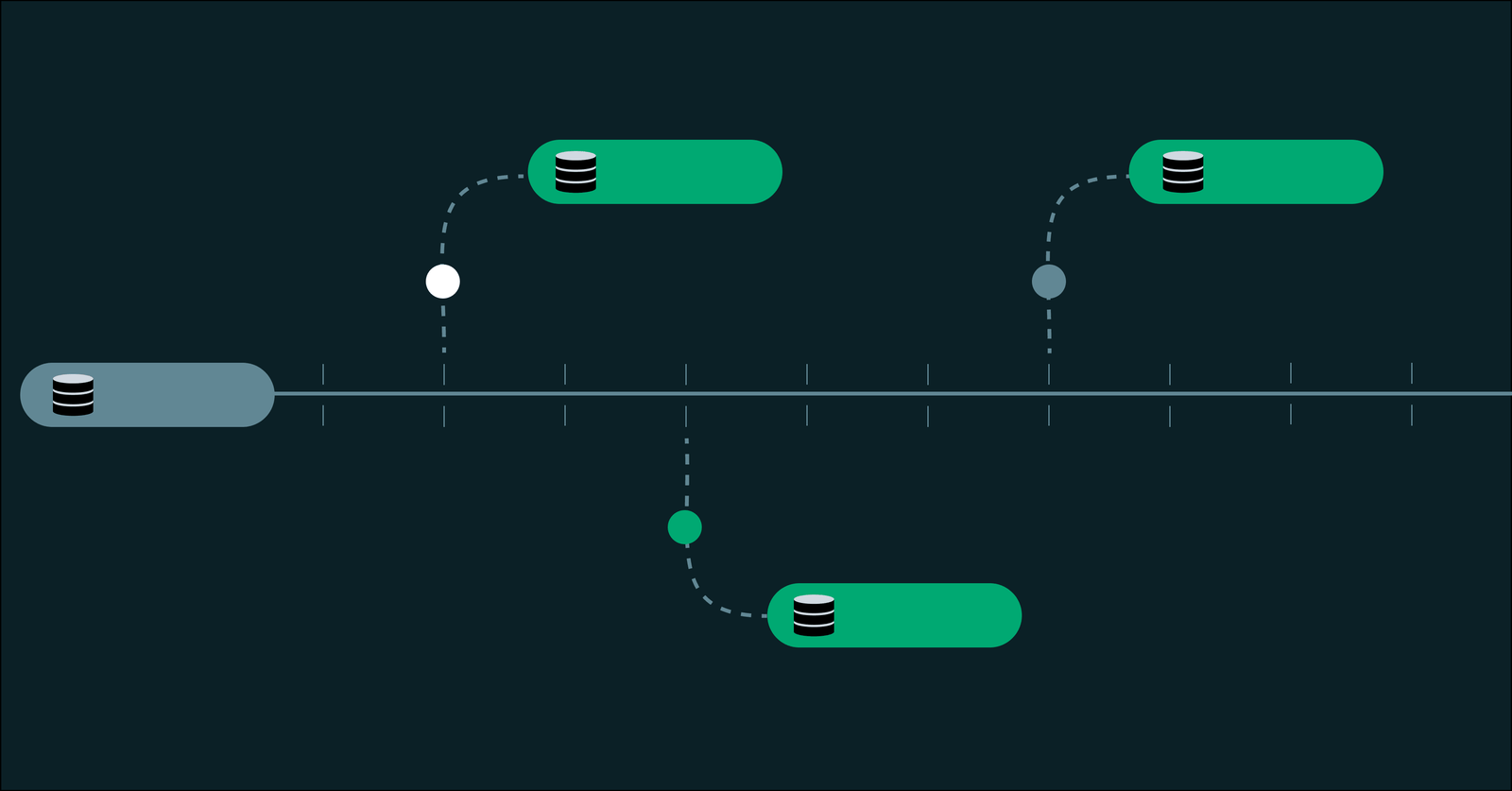
Databricks Lakebase Postgres introduces a transformative solution through database branching.
What database branching actually is
A database branch is distinct from a database copy, a nuance that significantly alters the economics of isolated environments. When duplicating a database, all data and schema are replicated into a new, independent instance, with time and cost scaling linearly with the database’s size. Each copy becomes a full clone, which begins to age the moment it is created.
In contrast, creating a branch in Lakebase results in a new, fully isolated Postgres environment that:
- Begins with the exact schema and data of its parent at a specific moment in time.
- Shares the same underlying storage, eliminating the need for duplication.
- Only records new data when modifications are made.
This approach, known as copy-on-write, allows branches to reference the same stored data as long as they remain undisturbed. When changes occur—be it a migration, row insertion, or table modification—only those alterations are recorded separately, while the rest remains shared with the parent.
Database copy vs. database branch
| Database copy (pg_dump, RDS snapshot) | Database branch (Lakebase) | |
| Time to create | Minutes to hours, scales with database size | Seconds, constant regardless of database size |
| Storage cost | Full duplicate of all data | Proportional to changes only (copy-on-write) |
| Isolation | Full, but expensive to maintain | Full, with independent compute and connection strings |
| Freshness | Stale from the moment it is created | Starts from the exact state of the parent at branch time |
| Cleanup | Manual teardown of instances and storage | Delete the branch; compute and storage are reclaimed automatically |
Practically, this means:
- Branch creation occurs in seconds, irrespective of database size. A 10GB database and a 2TB database branch in the same timeframe.
- Storage costs correlate to changes made, not the total data size. For instance, a branch that modifies 50MB of data in a 500GB database will utilize approximately 50MB of additional storage.
- Each branch is assigned its own Postgres connection string and compute endpoint, ensuring full isolation from one another and their parent.
- Idle branches automatically scale compute to zero, incurring costs only for active compute when a branch is in use.
Branches are designed for ease of creation, use, and disposal. They can be generated by developers, CI pipelines, AI agents, or automation tools, without the need for maintenance akin to precious environments. They are as disposable as Git branches.
The architecture that makes database branching possible
Traditional managed Postgres solutions, such as RDS and Azure Database for PostgreSQL, bind compute and storage together. The database process and its data reside on the same instance, with data stored as a single mutable filesystem. This architecture necessitates duplication for creating additional environments, as one must replicate the filesystem.
Conversely, a lakebase operates on a fundamentally different principle. It completely separates compute from storage, with all data written to a distributed, versioned storage engine that logs every change as a new version rather than overwriting existing data. This log-structured architecture enables database branching as a core primitive rather than a feature layered atop existing systems.
Due to the versioned nature of storage, multiple branches can reference the same underlying data without conflict. Independent compute allows each branch to run its own Postgres process, scaling autonomously. Non-production branches that remain idle can scale down to zero, restarting in milliseconds upon receiving a connection.
Not all implementations of database branching are created equal. Some platforms create full instance copies and label them as branches, while others only branch the schema without including data. Lakebase branches encompass both schema and data, employing copy-on-write at the storage layer to avoid duplication and providing independent, autoscaling compute for each branch. This design renders the creation of branches practical and scalable without necessitating additional infrastructure provisioning.
This architecture also facilitates time travel. With every version of the data retained within a configurable restore window, branches can be created from any point in the past, not merely the current state. This capability powers instant point-in-time recovery: rather than replaying WAL logs or restoring backups, one can create a branch at the desired timestamp and access it directly.
What database branching unlocks for your team
With database branching transforming from a costly copy operation into a swift, economical primitive, new workflows become feasible. Here are some common patterns that emerge:
One branch per developer.
Each engineer receives their own isolated environment populated with production-like data, eliminating the risk of overwriting one another’s changes in a shared development database. If a branch drifts too far from production, it can be reset with a single command to synchronize with the latest schema and data. This model remains cost-effective even for large teams due to branches scaling to zero when idle.
One branch per pull request.
Automate the creation of branches upon PR initiation and their deletion upon merging or closing. Preview deployments on platforms like Vercel or Netlify can each utilize their own database branch, ensuring that frontend previews are supported by realistic, isolated data. Migrations can be tested against actual data shapes and constraints rather than empty test fixtures. This workflow often serves as the initial adoption point for teams, leading to broader implementation of database branching.
One branch per test run.
CI pipelines can provision a fresh, isolated database for each run, eliminating residual state from prior tests. There’s no need to wait for an empty container image to initialize and populate with fake data, nor do shared data or test ordering dependencies lead to flaky results. Every test run begins from a consistent baseline. For tests requiring deterministic data, branches can be created from a fixed point in time or a specific Log Sequence Number (LSN).
Instant recovery.
Branches can be created from any point in time within a designated restore window, allowing for inspection of dropped tables, debugging of failed migrations, or auditing of historical data—all without impacting production. Schema diffs can be utilized to compare states before and after changes, with the ability to export necessary data from the recovery branch before deleting it. This entire process takes mere seconds, in stark contrast to the hours or days typically required for traditional point-in-time recovery.
Ephemeral environments for AI agents.
AI agents can programmatically provision databases via the Lakebase API, utilizing them for the duration of specific tasks before shutting them down. Platforms can build versioning atop snapshots, where each agent action creates a checkpoint, enabling users to switch between versions instantly. In the event of a faulty migration or data corruption, reverting is as simple as a single API call.
Getting started
With Databricks Lakebase, database branching transforms your Postgres database from the slowest segment of your development workflow into the fastest.
Creating your first branch takes less than a minute through the console, CLI, or API. Here’s a glimpse of the process from the CLI:
And just like that, you have an isolated Postgres environment that mirrors the full schema and data from production, ready for immediate use.
If you’re leveraging Postgres and are weary of the overhead involved in managing database environments, begin with a single development branch. From there, consider implementing one branch per PR. Many teams that initiate with one database branching workflow quickly expand to encompass additional practices.
Databricks Lakebase is serverless Postgres designed for agents and applications. Discover more at databricks.com/product/lakebase.