Amazon Bedrock Knowledge Bases introduces a fully managed Retrieval Augmented Generation (RAG) feature, seamlessly linking large language models (LLMs) with internal data sources. This innovative feature enriches the outputs of foundation models (FMs) by integrating contextual information from private datasets, thereby enhancing the relevance and accuracy of responses.
During AWS re:Invent 2024, Amazon announced that Bedrock Knowledge Bases now supports natural language querying for structured data retrieval from Amazon Redshift and Amazon SageMaker Lakehouse. This capability streamlines the development of generative AI applications, allowing them to access and utilize information from both structured and unstructured data sources. By employing natural language processing, Amazon Bedrock Knowledge Bases converts user queries into SQL queries, enabling data retrieval from supported sources without requiring users to grasp database structures or SQL syntax.
In this discussion, we will explore how to make your Amazon Aurora PostgreSQL-Compatible Edition data available for natural language querying via Amazon Bedrock Knowledge Bases while ensuring data freshness.
Structured data retrieval in Amazon Bedrock Knowledge Bases and Amazon Redshift Zero-ETL
The structured data retrieval feature in Amazon Bedrock Knowledge Bases facilitates natural language interactions with databases by transforming user queries into SQL statements. When linked to a supported data source such as Amazon Redshift, Amazon Bedrock Knowledge Bases examines the database schema, table relationships, query engine, and historical queries to comprehend the context and structure of the information. This insight enables the generation of precise SQL queries from natural language inquiries.
As of now, Amazon Bedrock Knowledge Bases supports structured data retrieval directly from Amazon Redshift and SageMaker Lakehouse. Although direct support for Aurora PostgreSQL-Compatible is not yet available, users can leverage the zero-ETL integration between Aurora PostgreSQL-Compatible and Amazon Redshift to make their data accessible for structured data retrieval. The Zero-ETL integration automatically replicates Aurora PostgreSQL tables to Amazon Redshift in near real-time, eliminating the need for complex extract, transform, and load (ETL) processes.
This architectural approach is particularly beneficial for organizations aiming to enable natural language querying of their structured application data stored in Amazon Aurora database tables. By merging zero-ETL integration with Amazon Bedrock Knowledge Bases, organizations can develop robust applications, such as AI assistants, that utilize LLMs to deliver natural language responses based on operational data.
Solution overview
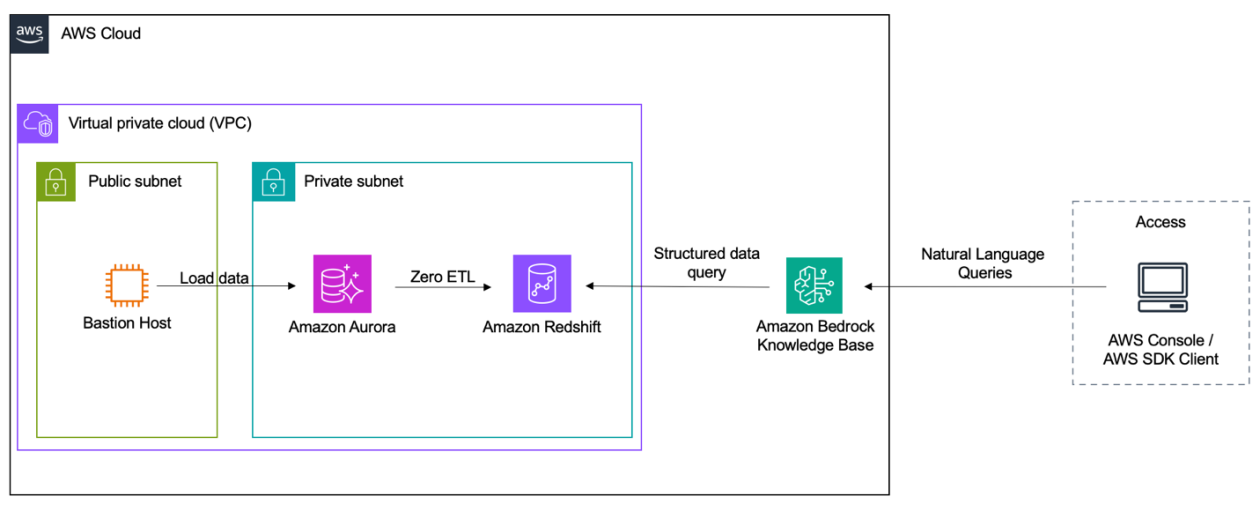
The following diagram illustrates the architecture for connecting Aurora PostgreSQL-Compatible to Amazon Bedrock Knowledge Bases using zero-ETL.
The workflow comprises these steps:
- Data is stored in Aurora PostgreSQL-Compatible within a private subnet, with a bastion host facilitating secure connections from the public subnet.
- Through zero-ETL integration, this data becomes available in Amazon Redshift, also situated in the private subnet.
- Amazon Bedrock Knowledge Bases utilizes Amazon Redshift as its structured data source.
- Users can interact with Amazon Bedrock Knowledge Bases via the AWS Management Console or an AWS SDK client, sending natural language queries that are processed to retrieve information stored in Amazon Redshift (sourced from Aurora).
Prerequisites
Ensure you are logged in with a user role that has permissions to create an Aurora database, execute DDL (CREATE, ALTER, DROP, RENAME) and DML (SELECT, INSERT, UPDATE, DELETE) statements, create a Redshift database, set up zero-ETL integration, and establish an Amazon Bedrock knowledge base.
Set up the Aurora PostgreSQL database
This section guides you through creating and configuring an Aurora PostgreSQL database with a sample schema for demonstration purposes. We will create three interconnected tables: products, customers, and orders.
Provision the database
To begin, create a new Aurora PostgreSQL database cluster and launch an Amazon Elastic Compute Cloud (Amazon EC2) instance that will act as the access point for managing the database. This EC2 instance simplifies the creation of tables and data management throughout this post.
For detailed instructions on setting up your database, refer to Creating and connecting to an Aurora PostgreSQL DB cluster.
Create the database schema
After connecting to your database via SSH on your EC2 instance (as described in the previous link), it’s time to establish your data structure. Use the following DDL statements to create the three tables:
-- Create Product table
CREATE TABLE product (
product_id SERIAL PRIMARY KEY,
product_name VARCHAR(100) NOT NULL,
price DECIMAL(10, 2) NOT NULL
);
-- Create Customer table
CREATE TABLE customer (
customer_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100) NOT NULL,
pincode VARCHAR(10) NOT NULL
);
-- Create Orders table
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
product_id INTEGER NOT NULL,
customer_id INTEGER NOT NULL,
FOREIGN KEY (product_id) REFERENCES product(product_id),
FOREIGN KEY (customer_id) REFERENCES customer(customer_id)
);Populate the tables with data
Once the tables are created, you can populate them with sample data. When inserting data into the orders table, ensure referential integrity by verifying that:
- The
product_idexists in theproducttable - The
customer_idexists in thecustomertable
Use the following example code to populate the tables:
INSERT INTO product (product_id, product_name, price) VALUES (1, 'Smartphone X', 699.99);
INSERT INTO product (product_id, product_name, price) VALUES (2, 'Laptop Pro', 1299.99);
INSERT INTO product (product_id, product_name, price) VALUES (3, 'Wireless Earbuds', 129.99);
INSERT INTO customer (customer_id, customer_name, pincode) VALUES (1, 'John Doe', '12345');
INSERT INTO customer (customer_id, customer_name, pincode) VALUES (2, 'Jane Smith', '23456');
INSERT INTO customer (customer_id, customer_name, pincode) VALUES (3, 'Robert Johnson', '34567');
INSERT INTO orders (order_id, product_id, customer_id) VALUES (1, 1, 1);
INSERT INTO orders (order_id, product_id, customer_id) VALUES (2, 1, 2);
INSERT INTO orders (order_id, product_id, customer_id) VALUES (3, 2, 3);
INSERT INTO orders (order_id, product_id, customer_id) VALUES (4, 2, 1);
INSERT INTO orders (order_id, product_id, customer_id) VALUES (5, 3, 2);
INSERT INTO orders (order_id, product_id, customer_id) VALUES (6, 3, 3);Maintain referential integrity when populating the orders table to prevent foreign key constraint violations. Similar examples can be used to build your schema and populate data.
Set up the Redshift cluster and configure zero-ETL
With your Aurora PostgreSQL database established, you can now set up the zero-ETL integration with Amazon Redshift. This integration automatically synchronizes your data between Aurora PostgreSQL-Compatible and Amazon Redshift.
Set up Amazon Redshift
Begin by creating an Amazon Redshift Serverless workgroup and namespace. For guidance, refer to Creating a data warehouse with Amazon Redshift Serverless.
Create a zero-ETL integration
The zero-ETL integration process involves two main steps:
- Create the zero-ETL integration from your Aurora PostgreSQL database to Redshift Serverless.
- After establishing the integration on the Aurora side, create the corresponding mapping database in Amazon Redshift. This step is essential for ensuring proper data synchronization between the two services.
The following screenshot illustrates the details of our zero-ETL integration.
Verify the integration
Upon completing the integration, you can verify its success through several checks. First, examine the zero-ETL integration details in the Amazon Redshift console. You should see an Active status for your integration, along with source and destination information, as depicted in the accompanying screenshot.
Additionally, you can utilize the Redshift Query Editor v2 to confirm that your data has been successfully populated. A simple query like SELECT * FROM customer; should return the synchronized data from your Aurora PostgreSQL database, as shown in the following screenshot.
Set up the Amazon Bedrock knowledge base with structured data
The final step involves creating an Amazon Bedrock knowledge base that facilitates natural language querying of our data.
Create the Amazon Bedrock knowledge base
Create a new Amazon Bedrock knowledge base with the structured data option. For detailed instructions, refer to Build a knowledge base by connecting to a structured data store. Following this, synchronize the query engine to enable data access.
Configure data access permissions
Before the synchronization process can succeed, grant appropriate permissions to the Amazon Bedrock Knowledge Bases AWS Identity and Access Management (IAM) role. This involves executing GRANT SELECT commands for each table in your Redshift database. Run the following command in Redshift Query Editor v2 for each table:
GRANT SELECT ON
| Natural Language Query | Generate SQL API Result | Retrieval and Response Generation | Model Used for Response Generation |
How many customers do we have? |
|
We currently have 11 unique customers. |
Amazon Nova Lite |
Which all customers have purchased the most products? |
|
Based on the data, the customers who have purchased the most products are Charlie Davis, Alice Brown, and John Doe, each having purchased 14 products. Following closely are Jane Smith, Grace Lee, and Bob Johnson, who have each purchased 13 products. Henry Taylor, Frank Miller, and Eva Wilson have each purchased 12 products, while Ivy Anderson has purchased 11 products. |
Amazon Nova Lite |
Who all have purchased more than one number of the most expensive product? |
|
The customers who have purchased more than one number of the most expensive product are Grace Lee, Jane Smith, Alice Brown, and Eva Wilson. |
Amazon Nova Micro |
Clean up
After utilizing this solution, it is advisable to clean up the resources created to avoid incurring ongoing charges.
About the authors
Girish B is a Senior Solutions Architect at AWS India Pvt Ltd based in Bengaluru. Girish collaborates with numerous ISV customers to design and architect innovative solutions on AWS.
Dani Mitchell is a Generative AI Specialist Solutions Architect at AWS, focused on accelerating enterprises worldwide on their generative AI journeys with Amazon Bedrock.